нет, немного не так. вообще у меня задача изначально автоматизировать проверку рамки/штампа на чертежах. Сначала я сделал скрипт на Python, который получает из конкретной указанной области листа все отрезки/тексты/мтексты и формировал из них excel таблицу. Вот этот код:
import win32com.client
import math
import re
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
from openpyxl.styles import Border, Side, Alignment
# -----------------------------
# Конфигурация
# -----------------------------
DWG_PATH = r"***\input_files\образец рамки.dwg"
OUTPUT_XLSX = "stamp.xlsx"
LINE_MIN_LENGTH = 10.0 # мм — фильтр против логотипа
ROUND_PRECISION = 2 # округление координат (0.01 мм)
STAMP_AREA = {
"min_x": min(230.0, 415.0),
"max_x": max(230.0, 415.0),
"min_y": min(60.0, 0.0),
"max_y": max(60.0, 5.0),
}
# -----------------------------
# Утилиты
# -----------------------------
def r(v):
return round(v, ROUND_PRECISION)
def line_length(p1, p2):
return math.dist(p1[:2], p2[:2])
def is_vertical(p1, p2):
return abs(p1[0] - p2[0]) < 0.01
def is_horizontal(p1, p2):
return abs(p1[1] - p2[1]) < 0.01
def in_stamp_area(x, y, area):
return (
area["min_x"] <= x <= area["max_x"] and
area["min_y"] <= y <= area["max_y"]
)
def transform_point(pt, blockref):
"""
Локальные координаты блока → глобальные координаты чертежа
"""
x, y = pt[0], pt[1]
sx = blockref.XScaleFactor
sy = blockref.YScaleFactor
angle = blockref.Rotation
ins_x, ins_y = blockref.InsertionPoint[0], blockref.InsertionPoint[1]
# масштаб
x *= sx
y *= sy
# поворот
xr = x * math.cos(angle) - y * math.sin(angle)
yr = x * math.sin(angle) + y * math.cos(angle)
# смещение
return xr + ins_x, yr + ins_y
def clear_mtext_formatting(text):
"""
Очистка форматирования MText NanoCAD/AutoCAD:
- Удаляет {\f...; и другие управляющие последовательности
- Декодирует \\uXXXX в символы Юникода
"""
if not text:
return ""
# Декодируем \\uXXXX → символы (например, \\u1058 → 'Т')
text = re.sub(r'\\u([0-9a-fA-F]{4})', lambda m: chr(int(m.group(1), 16)), text)
# Извлекаем текст после последней ';' внутри фигурных скобок
if text.startswith('{') and text.endswith('}'):
semicolon_pos = text.rfind(';')
if semicolon_pos != -1:
text = text[semicolon_pos + 1:-1].strip()
# Удаляем оставшиеся управляющие коды: \P (новая строка), \L...\l (нижний регистр) и др.
text = re.sub(r'\\[A-Z][^\\{}]*', '', text) # удаляем \P, \L...\l и подобные
text = re.sub(r'[{}]', '', text) # удаляем оставшиеся фигурные скобки
text = text.replace(r'\~', ' ') # неразрывный пробел → обычный
return text.strip()
# -----------------------------
# 1. Извлечение данных из блока
# -----------------------------
def extract_block_entities(doc):
grid_lines = []
texts = []
for obj in doc.PaperSpace:
if obj.EntityName != "AcDbBlockReference":
continue
blockref = win32com.client.CastTo(obj, "IAcadBlockReference")
block_def = doc.Blocks.Item(blockref.Name)
for ent in block_def:
# ---- ЛИНИИ
if ent.EntityName == "AcDbLine":
line = win32com.client.CastTo(ent, "IAcadLine")
p1 = line.StartPoint
p2 = line.EndPoint
if line_length(p1, p2) < LINE_MIN_LENGTH:
continue
if not (is_vertical(p1, p2) or is_horizontal(p1, p2)):
continue
# центр линии (локальный)
cx_l = (p1[0] + p2[0]) / 2
cy_l = (p1[1] + p2[1]) / 2
# → глобальный
cx, cy = transform_point((cx_l, cy_l), blockref)
if not in_stamp_area(cx, cy, STAMP_AREA):
continue
p1g = transform_point(p1, blockref)
p2g = transform_point(p2, blockref)
grid_lines.append((
r(p1g[0]), r(p1g[1]),
r(p2g[0]), r(p2g[1])
))
# ---- TEXT
elif ent.EntityName == "AcDbText":
t = win32com.client.CastTo(ent, "IAcadText")
try:
min_pt, max_pt = t.GetBoundingBox()
except:
# Если GetBoundingBox недоступен, используем InsertionPoint как ориентир
min_pt = t.InsertionPoint
max_pt = (min_pt[0] + 10, min_pt[1] + 5, 0)
cx_l = (min_pt[0] + max_pt[0]) / 2
cy_l = (min_pt[1] + max_pt[1]) / 2
cx, cy = transform_point((cx_l, cy_l), blockref)
if not in_stamp_area(cx, cy, STAMP_AREA):
continue
texts.append({
"text": t.TextString.strip(),
"center": (r(cx), r(cy)),
"source": "block"
})
# ---- MTEXT
# ---- MTEXT (в extract_block_entities)
elif ent.EntityName == "AcDbMText":
try:
mtext = win32com.client.CastTo(ent, "IAcadMText") # ← КЛЮЧЕВОЙ КАСТИНГ
min_pt, max_pt = mtext.GetBoundingBox()
cx_l = (min_pt[0] + max_pt[0]) / 2
cy_l = (min_pt[1] + max_pt[1]) / 2
cx, cy = transform_point((cx_l, cy_l), blockref)
if not in_stamp_area(cx, cy, STAMP_AREA):
continue
# Извлекаем текст ДО очистки
raw_text = mtext.TextString
clean_text = clear_mtext_formatting(raw_text)
# Отладка (временно раскомментируйте для проверки):
# print(f"MText (block): raw='{raw_text}' → clean='{clean_text}', center=({cx:.2f},{cy:.2f})")
if clean_text: # пропускаем пустые тексты
texts.append({
"text": clean_text,
"center": (r(cx), r(cy)),
"source": "block"
})
except Exception as e:
# Отладка ошибок:
# print(f"Ошибка обработки MText в блоке: {e}")
pass
return grid_lines, texts
# -----------------------------
# 2. Извлечение текстов напрямую с листа (вне блока)
# -----------------------------
def extract_paper_texts(doc):
"""
Извлечение текстов напрямую с листа (не входящих в BlockReference),
находящихся в области штампа.
"""
texts = []
for obj in doc.PaperSpace:
# Пропускаем блоки — их тексты уже обработаны в extract_block_entities
if obj.EntityName == "AcDbBlockReference":
continue
# ---- Однострочный текст
if obj.EntityName == "AcDbText":
try:
t = win32com.client.CastTo(obj, "IAcadText")
min_pt, max_pt = t.GetBoundingBox()
cx = (min_pt[0] + max_pt[0]) / 2
cy = (min_pt[1] + max_pt[1]) / 2
if not in_stamp_area(cx, cy, STAMP_AREA):
continue
texts.append({
"text": t.TextString.strip(),
"center": (r(cx), r(cy)),
"source": "paper"
})
except:
continue
# ---- Многострочный текст
# ---- MTEXT (в extract_paper_texts)
elif obj.EntityName == "AcDbMText":
try:
mtext = win32com.client.CastTo(obj, "IAcadMText") # ← КЛЮЧЕВОЙ КАСТИНГ
min_pt, max_pt = mtext.GetBoundingBox()
cx = (min_pt[0] + max_pt[0]) / 2
cy = (min_pt[1] + max_pt[1]) / 2
if not in_stamp_area(cx, cy, STAMP_AREA):
continue
raw_text = mtext.TextString
clean_text = clear_mtext_formatting(raw_text)
# Отладка:
# print(f"MText (paper): raw='{raw_text}' → clean='{clean_text}', center=({cx:.2f},{cy:.2f})")
if clean_text:
texts.append({
"text": clean_text,
"center": (r(cx), r(cy)),
"source": "paper"
})
except Exception as e:
# print(f"Ошибка обработки MText на листе: {e}")
continue
return texts
# -----------------------------
# 3. Построение сетки
# -----------------------------
def build_grid(lines):
x_coords = set()
y_coords = set()
for x1, y1, x2, y2 in lines:
if x1 == x2:
x_coords.add(x1)
if y1 == y2:
y_coords.add(y1)
xs = sorted(x_coords)
ys = sorted(y_coords, reverse=True)
return xs, ys
def find_cell(xs, ys, x, y):
for i in range(len(xs) - 1):
if xs[i] <= x <= xs[i + 1]:
for j in range(len(ys) - 1):
if ys[j] >= y >= ys[j + 1]:
return j + 1, i + 1
return None, None
# -----------------------------
# 4. Excel экспорт
# -----------------------------
def build_line_maps(lines):
vertical = set()
horizontal = set()
for x1, y1, x2, y2 in lines:
if x1 == x2:
vertical.add((x1, min(y1, y2), max(y1, y2)))
elif y1 == y2:
horizontal.add((y1, min(x1, x2), max(x1, x2)))
return vertical, horizontal
def has_vertical_border(x, y_top, y_bottom, vertical_lines):
for lx, ly1, ly2 in vertical_lines:
if abs(lx - x) < 0.01 and ly1 <= y_bottom and ly2 >= y_top:
return True
return False
def has_horizontal_border(y, x_left, x_right, horizontal_lines):
for ly, lx1, lx2 in horizontal_lines:
if abs(ly - y) < 0.01 and lx1 <= x_left and lx2 >= x_right:
return True
return False
def merge_cells(ws, xs, ys, vertical_lines, horizontal_lines):
rows = len(ys) - 1
cols = len(xs) - 1
merged = [[False] * cols for _ in range(rows)]
for r in range(rows):
for c in range(cols):
if merged[r][c]:
continue
r2 = r
c2 = c
# растягиваем вправо
while c2 + 1 < cols:
x_border = xs[c2 + 1]
y_top = ys[r]
y_bottom = ys[r + 1]
if has_vertical_border(x_border, y_top, y_bottom, vertical_lines):
break
c2 += 1
# растягиваем вниз
while r2 + 1 < rows:
y_border = ys[r2 + 1]
x_left = xs[c]
x_right = xs[c2 + 1]
if has_horizontal_border(y_border, x_left, x_right, horizontal_lines):
break
r2 += 1
if r2 > r or c2 > c:
ws.merge_cells(
start_row=r + 1,
start_column=c + 1,
end_row=r2 + 1,
end_column=c2 + 1
)
for rr in range(r, r2 + 1):
for cc in range(c, c2 + 1):
merged[rr][cc] = True
def autofit_columns(ws):
for col in ws.columns:
max_length = 0
col_letter = get_column_letter(col[0].column)
for cell in col:
if cell.value:
max_length = max(max_length, len(str(cell.value)))
ws.column_dimensions[col_letter].width = max_length + 2
def autofit_rows(ws):
for row in ws.rows:
max_height = 0
for cell in row:
if cell.value:
lines = str(cell.value).count("\n") + 1
max_height = max(max_height, lines)
ws.row_dimensions[row[0].row].height = max_height * 15
def export_to_excel(xs, ys, texts, vertical_lines, horizontal_lines):
wb = Workbook()
ws = wb.active
ws.title = "Штамп"
# Размеры столбцов (примерный расчет)
for i in range(len(xs) - 1):
ws.column_dimensions[get_column_letter(i + 1)].width = abs(xs[i + 1] - xs[i]) / 5
# Размеры строк
for j in range(len(ys) - 1):
ws.row_dimensions[j + 1].height = abs(ys[j] - ys[j + 1]) * 1.5
# Сначала создаем структуру объединенных ячеек
merge_cells(ws, xs, ys, vertical_lines, horizontal_lines)
# 1. Сортируем тексты по Y (сверху вниз), чтобы соблюдался порядок строк в ячейке
# ys у нас идут по убыванию, поэтому сортируем center[1] по убыванию
sorted_texts = sorted(texts, key=lambda x: x["center"][1], reverse=True)
for t in sorted_texts:
row, col = find_cell(xs, ys, *t["center"])
if row and col:
# Находим основную ячейку, если эта часть входит в MergeArea
target_cell = ws.cell(row=row, column=col)
for merged in ws.merged_cells.ranges:
if merged.min_row <= row <= merged.max_row and merged.min_col <= col <= merged.max_col:
target_cell = ws.cell(row=merged.min_row, column=merged.min_col)
break
# Если в ячейке уже что-то есть, добавляем через перенос строки
if target_cell.value:
target_cell.value = f"{target_cell.value}\n{t['text']}"
else:
target_cell.value = t["text"]
# Включаем перенос текста и центрирование (по желанию)
target_cell.alignment = Alignment(wrap_text=True, vertical='center', horizontal='left')
# ------------------------------------------
# Границы
thin = Side(border_style="thin", color="000000")
border = Border(top=thin, left=thin, right=thin, bottom=thin)
max_row = len(ys)
max_col = len(xs)
for row_idx in range(1, max_row):
for col_idx in range(1, max_col):
cell = ws.cell(row=row_idx, column=col_idx)
cell.border = border
# Автоподбор (опционально, может конфликтовать с ручной настройкой высоты)
autofit_columns(ws)
autofit_rows(ws)
wb.save(OUTPUT_XLSX)
# -----------------------------
# MAIN
# -----------------------------
def main():
nanocad = win32com.client.Dispatch("nanoCAD.Application")
doc = nanocad.Documents.Open(DWG_PATH)
# Извлечение линий и текстов из блока
lines, block_texts = extract_block_entities(doc)
# Извлечение текстов напрямую с листа
paper_texts = extract_paper_texts(doc)
# Объединение текстов (тексты с листа имеют приоритет при совпадении позиций)
all_texts = block_texts + paper_texts
xs, ys = build_grid(lines)
vertical, horizontal = build_line_maps(lines)
export_to_excel(xs, ys, all_texts, vertical, horizontal)
print("Линий в штампе:", len(lines))
print("Текстов из блока:", len(block_texts))
print("Текстов с листа:", len(paper_texts))
print("Всего текстов:", len(all_texts))
print("Excel создан:", OUTPUT_XLSX)
# Закрытие документа без сохранения
# doc.Close(False)
# nanocad.Quit()
if __name__ == "__main__":
main()
он работает корректно с горизонтальным листом А3 и рамкой моего предприятия. (если что поправьте меня в терминологии что такое штамп и рамка). То есть все эти объекты на чертеже из которых состоял штамп справа в углу были объединены в один элемент нанокада, называемый Блок (BlockReference если быть точным).
Потом мне сообщили что их инженеры используют конкретные рамки и штампы в зависимости от страны, для которой делают и прочих факторов. Все эти заготовки у них есть в этой базе СПДС (где я так понял они и занимаются конечным оформлением чертежа) в виде нескольких папок.
Вот я хочу попробовать сделать программу, которая будет получать на вход чертеж в формате dwg, какие-то данные о нем и проверять на наличие в нем определенного блока из этих папок (я так понимаю вставляя какой-либо объект из этой папки он также вставляется на чертёж Блоком - BlockReference) и его координаты вставки.
Для этого мне нужно как-то программно получить всю структуру этих папок себе чтобы я мог проверить с тем что фактически из этого есть на чертеже.
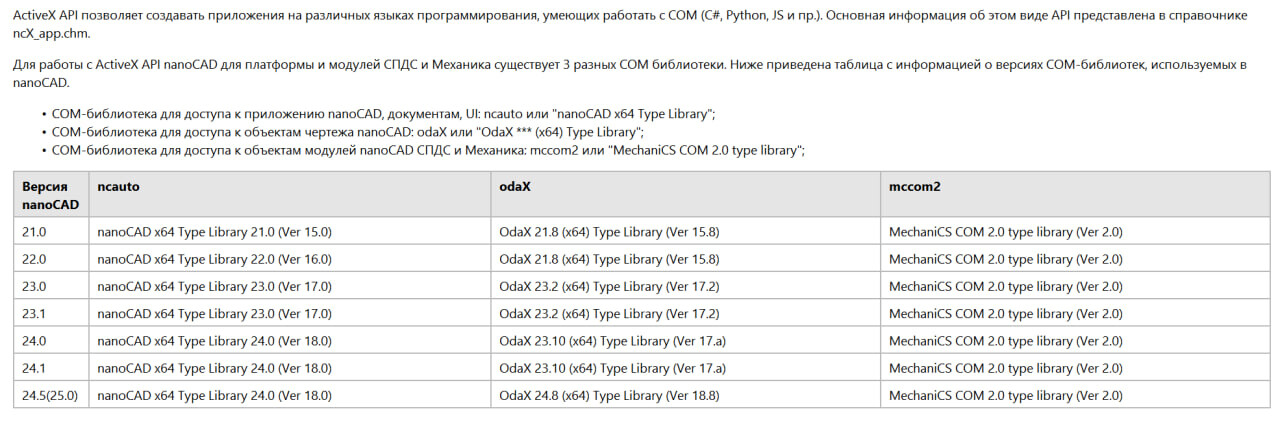
Плюс мой вопрос по поводу наличия какой-либо документации остаётся открытым.